
최근 프로젝트 작업 중 팀원이 만든 Jupyter notebook을 AWS lambda로 옮겨 자동화를 시켜야 할 Task가 생겼습니다. Jupyter는 python코드로 변환해서 사용하면 되고, 다른 과정도 처음에는 대수롭지 않게 생각하고 작업을 진행했지만.. lambda로 이전하는 작업 중 꽤 고되고 힘든 과정이었습니다.
Jupyter의 작업 내용은 무엇인가?
한 사이트를 켜고 musicXML파일을 올리고 사이즈를 적당히 줄인 뒤 svg형태의 파일을 저장하고 svg의 css_selector로 요소를 뽑아내서 txt 파일로 또 저장하는 작업.
lambda로 이전 시 무엇이 문제인가?
- 로컬 환경에 저장된 musicXML을 이용해 로컬환경에 svg, txt를 저장하는 작업을 lambda로 어떻게 옮기는가, lambda의 데이터 스토리지는 어떤 종류가 있을까?
- selenium 등의 파이썬 패키지들을 어떻게 lambda에 이식시키는가?
- lambda환경에서 chrome을 어떻게 설치하거나 인식하도록 세팅할 것인가?
- 가뜩이나 느린 크롤링 과정, lambda의 제한 시간 안에 완료는 될까?
1. 로컬 환경에 저장된 musicXML을 이용해 로컬환경에 svg, txt를 저장하는 작업을 lambda로 어떻게 옮기는가, lambda의 데이터 스토리지는 어떤 종류가 있을까?
처음은 단순하게 s3를 사용하여 접근해서 사용하는 방법을 생각했었는데, python의 boto3는 s3의 파일을 다운로드하는 용도로 사용되었습니다. 그렇다면 lambda의 어떤 스토리지에 저장을 해야 하는지 열심히 찾아보다가 발견한 lambda의 데이터 스토리지 선택법을 보고 lambda가 실행될 때마다 tmp/라는 임시 스토리지가 제공된다는 것을 알았습니다. EFS도 있지만 이 서비스는 따로 비용이 발생하기도 하고 VPC도 설정해야 해서 lambda실행 후 네트워크를 연결하는 과정에서 충돌도 발생해 사용하지 않았습니다.
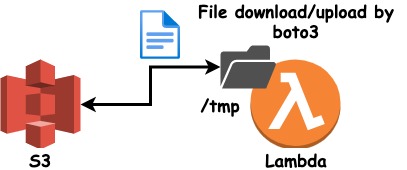
s3로부터 다운로드한 자료를 /tmp에 저장하고, chrome에서 실행된 사이트에 올릴 파일을 /tmp에서 꺼내와 사용할 수 있게 됩니다.
2. selenium 등의 파이썬 패키지들을 어떻게 lambda에 이식시키는가?
lambda에는 layer라는 npm이나 pip 패키지를 설치한 zip 파일을 올릴 수있는 시스템이 있습니다. 하지만 정해진 파일구조를 따라 압축해야하고, 패키지 하나를 추가해야할 때마다 새로 폴더에 패키지를 설치해서 압축해서 layer에 올리고, layer의 버전을 변경해야 하는 과정이 매우매우 귀찮습니다. 하지만 다른 쉬운 방법은 또 없는것 같고.. gcp는 패키지 관리가 단순하다고 하던데 lambda도 개선이 이루어졌으면 좋겠습니다. 그렇게 selenium,boto3 등을 다운로드 받아 zip파일을 layer로 올리면서 해결합니다. 참, 이 과정에서 layer로 올리고도 모듈을 인식 못한다고 오류를 뱉어내면 파일 구조의 문제이니 공식문서를 참조해서 파일 구조를 변경하면 됩니다.
3. Lambda환경에서 chrome을 어떻게 설치하거나 인식하도록 세팅할 것인가?
다행히 chrome driver라는 리눅스 실행파일을 layer로 깔아 두고 파이썬 코드에 설정값을 넣어주면 실행이 가능하다는 자료를 찾았습니다. 원래의 코드에서는 webdriver_manager라는 패키지를 사용했었는데 chrome --version 명령어를 lambda가 못 읽는다며 오류를 뱉어내서 못쓰고 chrome driver를 layer로 설치해 이를 해결했습니다.
4. 가뜩이나 느린 크롤링 과정, lambda의 제한 시간 안에 완료는 될까? 요금은 얼마나 나올 것인가?
위의 문제를 해결하고도 lambda는 제대로 돌아가지 않았습니다. 아니, 제한시간을 15분으로 Max 설정을 해도 timeout을 내며 뻗어버린 것이었습니다. 처음엔 단순히 lambda가 너무 느린가 보다 생각을 했었는데 원인은 다른 곳에 있었습니다.

lambda의 기본 메모리 제한이 128mb여서 chrome을 켜자마자 터져버린 것이었습니다.. 정말 search를 엄청해도 메모리 얘기는 없어서 아예 인지를 못하고 있었는데 used memory가 128mb.... 결국 메모리를 1024mb로 넉넉히 풀고 나서야 6분가량 정상적으로 동작을 마쳤습니다.
글로 정리하니 별 것 아닌 과정 같지만 이 람다 함수 1개만으로 거의 일주일은 잡아먹었던 것 같습니다. 30개 정도의 람다 함수를 작성하며 람다로 이것저것 요리해보는 건 다 해본 것 같지만 아직 lambda위에 docker 컨테이너를 띄우는 작업이 남아있습니다. 이 과정에서도 글 쓸 거리가 생기면 lambda docker 포스트로 돌아오겠습니다.
오늘의 교훈: 에러 메시지를 꼼꼼히 읽자..
lambda에 chrome과 selenium 환경설정을 하는 코드를 github에 올려두었습니다. 필요하신 분들은 참고하시길 바랍니다.
https://github.com/newdeal123/Lambda-Selenium-Chromedriver
GitHub - newdeal123/Lambda-Selenium-Chromedriver: Setting up the Selenium,Chromedriver environment in AWS Lambda.
Setting up the Selenium,Chromedriver environment in AWS Lambda. - GitHub - newdeal123/Lambda-Selenium-Chromedriver: Setting up the Selenium,Chromedriver environment in AWS Lambda.
github.com
'🐳AWS' 카테고리의 다른 글
| [AWS] Lambda위에 자체 환경(Ubuntu)의 docker 컨테이너 올리기 (0) | 2021.11.23 |
|---|---|
| [AWS] Step Function으로 Lambda 워크플로 자동화하기 (0) | 2021.09.08 |
| [AWS][테라폼] 🐬 테라폼으로 AWS EC2 인스턴스 생성,삭제하기 (0) | 2021.06.19 |
| [AWS] 나의 클라우드 아키텍처 입문기 (0) | 2021.06.16 |
| [AWS] AWS에 63만원 요금폭탄 맞은 후기 (4) | 2021.06.07 |