

CronJob은 반복 일정에 따라 Job을 만드는 Kubernetes의 워크로드 리소스입니다. 크론잡은 잡을 크론 형식으로 쓰인 주기적인 일정에 따라 동작시키죠.
예를 들어 하단의 크론잡 매니페스트 예제는 현재 시간과 hello 메시지를 1분마다 출력합니다.
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
CronJob과 Job의 관계가 Deployment와 Pod의 관계와 비슷하지 않나요? CronJob은 Job을 생성하는 컨트롤러의 성격을 띠고 있습니다. schedule 필드에 정의된 표준 Unix Cron 형식 표현식을 기반으로 작업을 생성하고 삭제하는 일들을 담당하죠.
그렇다면 Kubernetes는 CronJob을 어떤 형식으로 구현하고 있을까요?
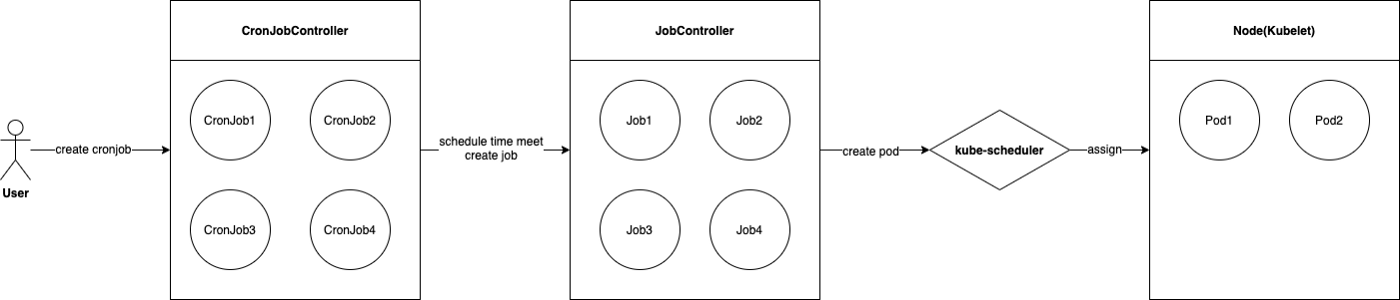
1. 사용자가 CronJob 유형의 리소스를 생성합니다.
2. CronJob Controller가 10초마다 모든 CronJob 리소스를 순회 하여 예약해야 하는 리소스가 있는지 확인합니다. 만약 CronJob의 조건이 현재 시간과 일치하는 경우 해당 작업 리소스를 생성합니다.
3. JobController가 해당 Job을 기반으로 해당 Pod 리소스를 생성합니다.
4. kube-scheduler가 스케줄링을 담당해 실행 가능한 노드에 Pod 생성 명령을 지시합니다.
5. 노드에서 Kubelet이 Pod 런타임 환경 생성 및 컨테이너 시작을 담당 합니다.
CronJob 컨트롤러는 10초마다 CronJob 리소스를 순회합니다. 즉, 10초보다 낮은 Interval로 Job을 실행시키려 한다면 CronJob으로는 해당 워크로드의 실행을 보장할 수 없습니다. (참고로 AWS의 EventBridge Cron 식은 1분의 간격을 가지고 있습니다.)
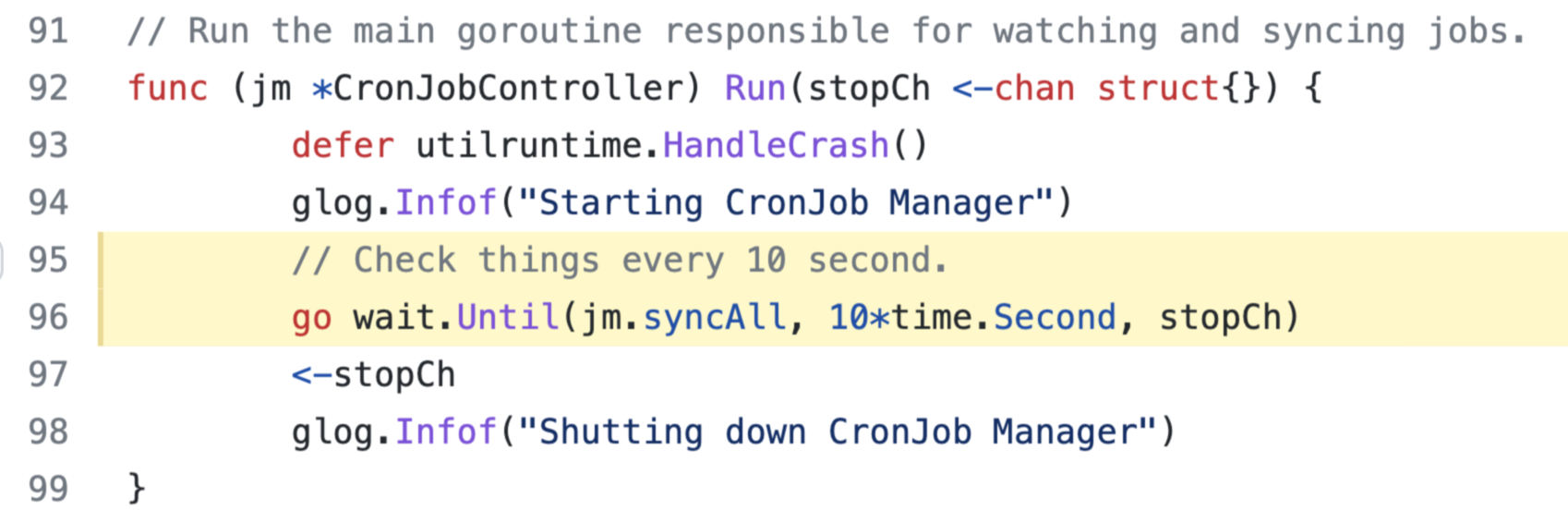
그리고 Kubernetes Docs에는 모든 CronJob이 완벽하게 동작하지 않을 수도 있음을 주의시키고 있습니다.
크론 잡은 일정의 실행시간마다 "약" 한 번의 Job 오브젝트를 생성한다. "약"이라고 하는 이유는 특정 환경에서는 두 개의 Job이 만들어지거나, Job이 생성되지 않기도 하기 때문이다. 보통 이렇게 하지 않도록 해야겠지만, 완벽히 그럴 수는 없다. 따라서 잡은 멱등원 이 된다.
출처 : Kubernetes Docs

이게 무슨.,.. 무슨... 소린가 싶습니다. 더 파고들기 위해서는 CronJob의 구성 명세 중 다음을 먼저 알아야 합니다.
- spec.concurrencyPolicy:
- Forbid: 만약 현재 Job이 여전히 실행 중이라면, 새로운 Job의 실행을 스킵합니다.
- Replace: 만약 현재 Job이 여전히 실행중이라면, 인스턴스의 실행을 중지시키고 새로이 생성합니다.
- Allow: Job의 여러 인스턴스가 병렬로 실행될 수 있게 합니다.
- spec.jobTemplate.spec.activeDeadlineSeconds:
- Kubernetes가 작업을 중지하기 전에 작업의 최대 기간입니다.
- 이 Deadline은 Job 생성과 관련된 것입니다. 예를 들어 이미지를 풀링해야 하는 경우 포드가 시작하는 데 시간이 걸릴 수 있습니다.
- 구체적인 작업 시간을 알고 있는 경우에만 이 값을 설정해야 합니다.
- spec.jobTemplate.spec.backoffLimit:
- Pod가 실패하거나(exit code > 0) Pod의 deadline이 초과된 경우, 이 Job을 최종적으로 실패라고 표시하기 전의 최대 재시도 횟수입니다.
- 기본값은 6이고, 재시도를 허용하지 않으려면 0으로 설정해야 합니다.
- spec.jobTemplate.spec.template.spec.activeDeadlineSeconds:
- Kubernetes가 Pod를 중지하기 전까지 Pod의 최대 지속 시간입니다.
- 만약 Job backoffLimit가 0보다 크다면, 그 값에 도달할 때까지 새로운 Pod가 생성됩니다.
즉, concurrencyPolicy의 타입이 Forbid라면 Job이 실행되지 않을 수도 있으며, 타입이 Allow라면 Job이 여러 번 실행될 수 있습니다.
이중에서도 특히 Forbid타입에서 Job이 어떤 경우에서 실행되지 않을 수 있는지 알아봅시다.
만약 concurrencyPolicy의 타입이 Forbid일 때, backoffLimit와 activeDeadlineSeconds는 어떻게 알고리즘에 관여될까요? 밑의 다이어그램을 따라가면 이해할 수 있습니다.
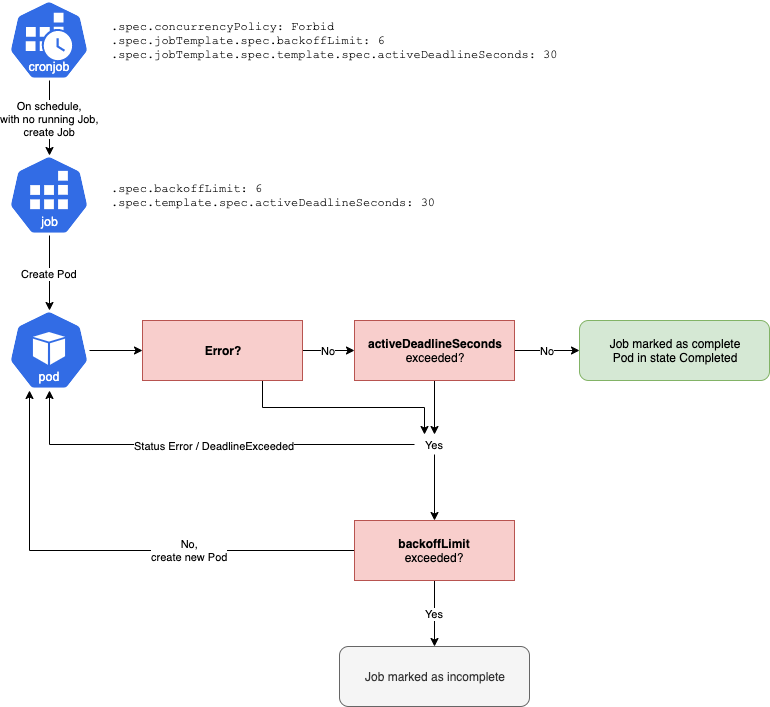
backoffLimit와 activeDeadlineSeconds이 어떻게 작동하는지는 알았습니다. 구체적인 사례를 중심으로 이 값들이 CronJob과 Job에 어떻게 동작하는지, 과정을 살펴봅시다.
Job에 배정된 Pod의 동작 시간이 약 10분이라고 합니다. 이때 CronJob을 매 5분마다 Job이 실행되도록 하고, activeDeadlineSeconds를 540s으로(= 9 min) 설정했을 때는,
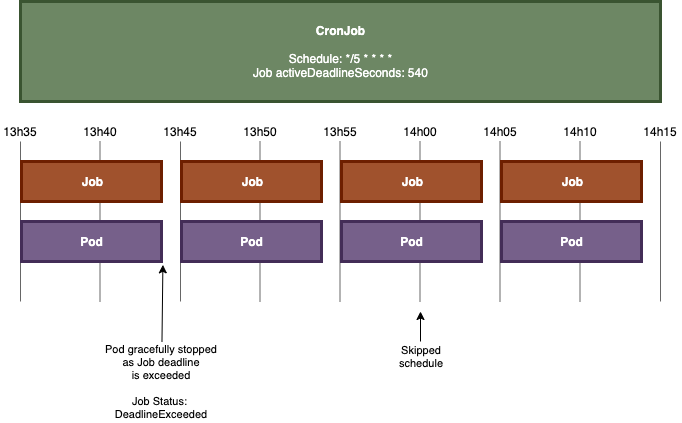
Pod의 러닝타임이 Job의 Deadline을 넘겨버렸기 때문에 DeadlineExceeded를 뱉고 종료됩니다. Pod의 동작시간이 약 10분이어서, 정상적으로 종료가 되기 도전에 에러를 뱉고 강제 종료시켜 버리게 됩니다.
Pod의 동작 시간을 그대로 약 10분, CronJob도 매 5분인 것은 동일하지만, activeDeadlineSeconds만 900s( = 15 min)로 바꿨을 때를 볼까요?
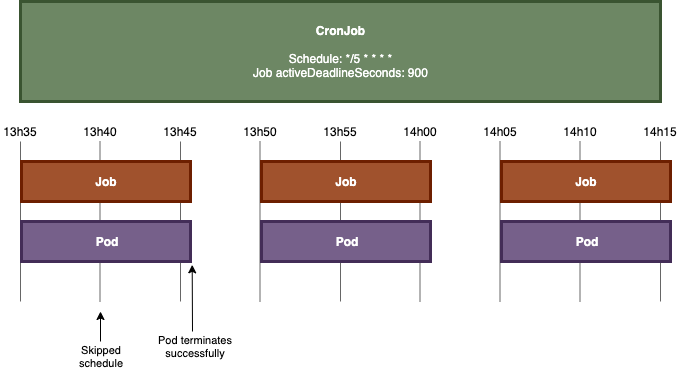
정상적으로 Pod가 제 일을 끝내고 종료시킨 것을 확인할 수 있습니다. cron 주기가 5분이지만 Job은 15분마다 실행되고 있는 것을 알 수 있습니다.
자 이젠, activeDeadlineSeconds을 다시 줄여 420이라 두고, backofflimit 값을 새로이 2로 줘봅시다.
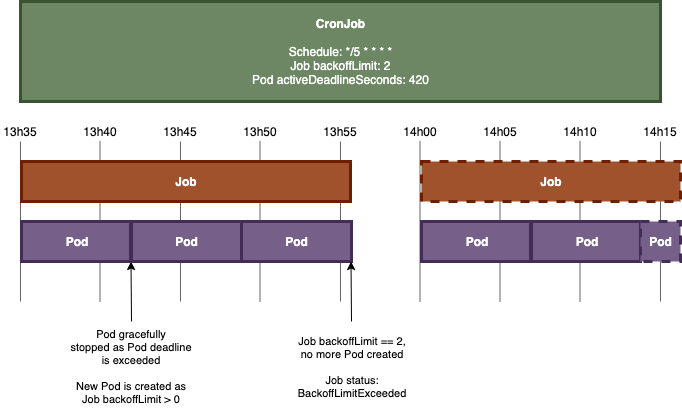
Pod가 정상 종료하기까지는 약 10분이 소요되지만, Deadline이 420s( = 7 min) 이므로 종료됩니다. 다만 여기서 backkoffLimit를 2로 줬으므로 이전처럼 DeadlineExceeded 에러를 바로 뱉는 것이 아니라, 새로 Pod를 실행합니다. 새로 생성된 Pod 역시 종료되고, backoffLimit을 넘게 된다면 더 이상 Pod가 생성되지 않고, BackoffLimitExceeded 에러를 뱉고 종료됩니다.
이번엔 앞 조건은 같고 activeDeadlineSeconds만 900으로 줘봅시다.
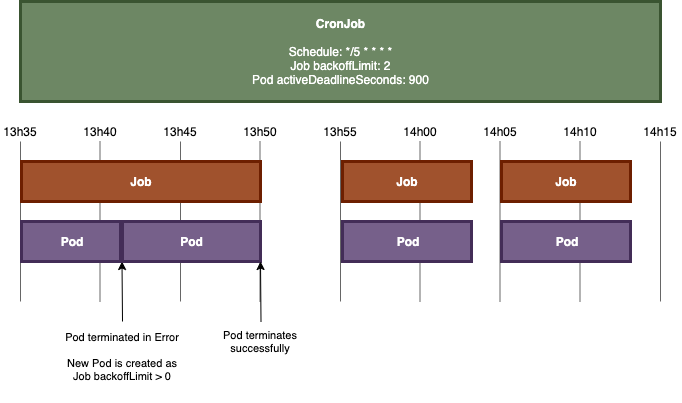
Job이 Pod를 생성했지만 Pod가 부득이한 에러로 종료되었음에도 불구하고 다시 새로운 Pod를 할당시켜 성공적으로 Job을 완수하는 모습입니다.
즉, backoffLimit와 activeDeadlineSeconds의 값들을 Pod의 실행시간과 관련해 적절하게 조합시켜야만 우리가 의도한 대로 Job을 실행시킬 수 있음을 의미합니다. 재미있지 않나요?
마지막으로 CronJob의 Best Practices에 대해 알아봅시다.
동시에 모든 작업을 실행시키지는 말 것
보통 CronJob을 구성할 때 cron 식을 매 5분마다, 매 10분마다 혹은 매일, 매주 같은 형식으로 많이 구성합니다.
예를 들어 * * * * * , */5 * * * * , 0 * * * * 같은 cron 식으로 구성된 CronJob들이 있다면,
클러스터에서 CronJob의 수가 증가하기 시작하면 위의 모든 cron 표현식이 일치하는 매 시간 혹은 5분마다 리소스 사용량이 최고조에 달하는 것을 알 수 있습니다.
이로 인해 불필요한 클러스터 자동 확장, 다른 워크로드에 영향을 미치는 높은 네트워크 처리량, 경합 상태 등이 발생할 수 있습니다. 그러니 같은 cron 식들을 분할하는 것이 좋습니다. 아래 예시와 같은 방법으로요.
- 5분마다 : 4,9,14,19,24,29,34,39,44,49,54,49 * * * *
- 6분마다: */6 * * * *
리소스를 효율적으로 사용할 것
CronJob은 Pod를 통해 실행되므로 리소스 요청 및 제한을 정의하는 것이 좋습니다.
대부분의 cron 워크로드는 단일 스레드(예: PHP script)에서 실행됩니다. 즉, 최대 1개의 코어를 사용하므로 너무 많은 리소스를 요청할 필요가 없습니다. pod 명세를 통해 더 낮은 CPU 제한을 할당해 주는 것이 필요합니다.
예를 들어 1이 아니라 0.25 CPU로도 실행시간이 크게 바뀌지 않거나 실행 시간이 길어져도 큰 상관이 없는 경우, 0.25 CPU로 할당했을 때는 여러 CronJob들이 실행될 수 있으므로 클러스터 auto scaling을 하지 않아도 됩니다. 그러므로 가능한 한 리소스 요청량을 제한하는 것이 좋습니다.
출처
https://michael.bouvy.net/post/deep-dive-kubernetes-cronjob
https://aws.plainenglish.io/kubernetes-deep-dive-cronjob-4df5f64039d6
https://kubernetes.io/ko/docs/concepts/workloads/controllers/cron-jobs/
'🏋️♀️ DevOps, SRE' 카테고리의 다른 글
| [k8s] 당신의 pod에서 nslookup이 실패하는 이유 (0) | 2023.02.18 |
|---|---|
| 신입 데브옵스 (DevOps) 엔지니어 되기 - (1) (27) | 2023.02.06 |
| 주니어 DevOps 엔지니어가 바라 본 CPU 아키텍처 (docker pull이 안 된다!) (1) | 2022.10.21 |
| [AWS][DevOps] Terraform으로 EKS 환경 구성하기 - (1) (0) | 2022.08.14 |
| [DevOps] 내부 개발자 플랫폼 (IDP) : 조직이 더 효율적으로 일하는 방법 (0) | 2022.07.22 |
CronJob은 반복 일정에 따라 Job을 만드는 Kubernetes의 워크로드 리소스입니다. 크론잡은 잡을 크론 형식으로 쓰인 주기적인 일정에 따라 동작시키죠.
예를 들어 하단의 크론잡 매니페스트 예제는 현재 시간과 hello 메시지를 1분마다 출력합니다.
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
CronJob과 Job의 관계가 Deployment와 Pod의 관계와 비슷하지 않나요? CronJob은 Job을 생성하는 컨트롤러의 성격을 띠고 있습니다. schedule 필드에 정의된 표준 Unix Cron 형식 표현식을 기반으로 작업을 생성하고 삭제하는 일들을 담당하죠.
그렇다면 Kubernetes는 CronJob을 어떤 형식으로 구현하고 있을까요?
1. 사용자가 CronJob 유형의 리소스를 생성합니다.
2. CronJob Controller가 10초마다 모든 CronJob 리소스를 순회 하여 예약해야 하는 리소스가 있는지 확인합니다. 만약 CronJob의 조건이 현재 시간과 일치하는 경우 해당 작업 리소스를 생성합니다.
3. JobController가 해당 Job을 기반으로 해당 Pod 리소스를 생성합니다.
4. kube-scheduler가 스케줄링을 담당해 실행 가능한 노드에 Pod 생성 명령을 지시합니다.
5. 노드에서 Kubelet이 Pod 런타임 환경 생성 및 컨테이너 시작을 담당 합니다.
CronJob 컨트롤러는 10초마다 CronJob 리소스를 순회합니다. 즉, 10초보다 낮은 Interval로 Job을 실행시키려 한다면 CronJob으로는 해당 워크로드의 실행을 보장할 수 없습니다. (참고로 AWS의 EventBridge Cron 식은 1분의 간격을 가지고 있습니다.)
그리고 Kubernetes Docs에는 모든 CronJob이 완벽하게 동작하지 않을 수도 있음을 주의시키고 있습니다.
크론 잡은 일정의 실행시간마다 "약" 한 번의 Job 오브젝트를 생성한다. "약"이라고 하는 이유는 특정 환경에서는 두 개의 Job이 만들어지거나, Job이 생성되지 않기도 하기 때문이다. 보통 이렇게 하지 않도록 해야겠지만, 완벽히 그럴 수는 없다. 따라서 잡은 멱등원 이 된다.
출처 : Kubernetes Docs
이게 무슨.,.. 무슨... 소린가 싶습니다. 더 파고들기 위해서는 CronJob의 구성 명세 중 다음을 먼저 알아야 합니다.
- spec.concurrencyPolicy:
- Forbid: 만약 현재 Job이 여전히 실행 중이라면, 새로운 Job의 실행을 스킵합니다.
- Replace: 만약 현재 Job이 여전히 실행중이라면, 인스턴스의 실행을 중지시키고 새로이 생성합니다.
- Allow: Job의 여러 인스턴스가 병렬로 실행될 수 있게 합니다.
- spec.jobTemplate.spec.activeDeadlineSeconds:
- Kubernetes가 작업을 중지하기 전에 작업의 최대 기간입니다.
- 이 Deadline은 Job 생성과 관련된 것입니다. 예를 들어 이미지를 풀링해야 하는 경우 포드가 시작하는 데 시간이 걸릴 수 있습니다.
- 구체적인 작업 시간을 알고 있는 경우에만 이 값을 설정해야 합니다.
- spec.jobTemplate.spec.backoffLimit:
- Pod가 실패하거나(exit code > 0) Pod의 deadline이 초과된 경우, 이 Job을 최종적으로 실패라고 표시하기 전의 최대 재시도 횟수입니다.
- 기본값은 6이고, 재시도를 허용하지 않으려면 0으로 설정해야 합니다.
- spec.jobTemplate.spec.template.spec.activeDeadlineSeconds:
- Kubernetes가 Pod를 중지하기 전까지 Pod의 최대 지속 시간입니다.
- 만약 Job backoffLimit가 0보다 크다면, 그 값에 도달할 때까지 새로운 Pod가 생성됩니다.
즉, concurrencyPolicy의 타입이 Forbid라면 Job이 실행되지 않을 수도 있으며, 타입이 Allow라면 Job이 여러 번 실행될 수 있습니다.
이중에서도 특히 Forbid타입에서 Job이 어떤 경우에서 실행되지 않을 수 있는지 알아봅시다.
만약 concurrencyPolicy의 타입이 Forbid일 때, backoffLimit와 activeDeadlineSeconds는 어떻게 알고리즘에 관여될까요? 밑의 다이어그램을 따라가면 이해할 수 있습니다.
backoffLimit와 activeDeadlineSeconds이 어떻게 작동하는지는 알았습니다. 구체적인 사례를 중심으로 이 값들이 CronJob과 Job에 어떻게 동작하는지, 과정을 살펴봅시다.
Job에 배정된 Pod의 동작 시간이 약 10분이라고 합니다. 이때 CronJob을 매 5분마다 Job이 실행되도록 하고, activeDeadlineSeconds를 540s으로(= 9 min) 설정했을 때는,
Pod의 러닝타임이 Job의 Deadline을 넘겨버렸기 때문에 DeadlineExceeded를 뱉고 종료됩니다. Pod의 동작시간이 약 10분이어서, 정상적으로 종료가 되기 도전에 에러를 뱉고 강제 종료시켜 버리게 됩니다.
Pod의 동작 시간을 그대로 약 10분, CronJob도 매 5분인 것은 동일하지만, activeDeadlineSeconds만 900s( = 15 min)로 바꿨을 때를 볼까요?
정상적으로 Pod가 제 일을 끝내고 종료시킨 것을 확인할 수 있습니다. cron 주기가 5분이지만 Job은 15분마다 실행되고 있는 것을 알 수 있습니다.
자 이젠, activeDeadlineSeconds을 다시 줄여 420이라 두고, backofflimit 값을 새로이 2로 줘봅시다.
Pod가 정상 종료하기까지는 약 10분이 소요되지만, Deadline이 420s( = 7 min) 이므로 종료됩니다. 다만 여기서 backkoffLimit를 2로 줬으므로 이전처럼 DeadlineExceeded 에러를 바로 뱉는 것이 아니라, 새로 Pod를 실행합니다. 새로 생성된 Pod 역시 종료되고, backoffLimit을 넘게 된다면 더 이상 Pod가 생성되지 않고, BackoffLimitExceeded 에러를 뱉고 종료됩니다.
이번엔 앞 조건은 같고 activeDeadlineSeconds만 900으로 줘봅시다.
Job이 Pod를 생성했지만 Pod가 부득이한 에러로 종료되었음에도 불구하고 다시 새로운 Pod를 할당시켜 성공적으로 Job을 완수하는 모습입니다.
즉, backoffLimit와 activeDeadlineSeconds의 값들을 Pod의 실행시간과 관련해 적절하게 조합시켜야만 우리가 의도한 대로 Job을 실행시킬 수 있음을 의미합니다. 재미있지 않나요?
마지막으로 CronJob의 Best Practices에 대해 알아봅시다.
동시에 모든 작업을 실행시키지는 말 것
보통 CronJob을 구성할 때 cron 식을 매 5분마다, 매 10분마다 혹은 매일, 매주 같은 형식으로 많이 구성합니다.
예를 들어 * * * * * , */5 * * * * , 0 * * * * 같은 cron 식으로 구성된 CronJob들이 있다면,
클러스터에서 CronJob의 수가 증가하기 시작하면 위의 모든 cron 표현식이 일치하는 매 시간 혹은 5분마다 리소스 사용량이 최고조에 달하는 것을 알 수 있습니다.
이로 인해 불필요한 클러스터 자동 확장, 다른 워크로드에 영향을 미치는 높은 네트워크 처리량, 경합 상태 등이 발생할 수 있습니다. 그러니 같은 cron 식들을 분할하는 것이 좋습니다. 아래 예시와 같은 방법으로요.
- 5분마다 : 4,9,14,19,24,29,34,39,44,49,54,49 * * * *
- 6분마다: */6 * * * *
리소스를 효율적으로 사용할 것
CronJob은 Pod를 통해 실행되므로 리소스 요청 및 제한을 정의하는 것이 좋습니다.
대부분의 cron 워크로드는 단일 스레드(예: PHP script)에서 실행됩니다. 즉, 최대 1개의 코어를 사용하므로 너무 많은 리소스를 요청할 필요가 없습니다. pod 명세를 통해 더 낮은 CPU 제한을 할당해 주는 것이 필요합니다.
예를 들어 1이 아니라 0.25 CPU로도 실행시간이 크게 바뀌지 않거나 실행 시간이 길어져도 큰 상관이 없는 경우, 0.25 CPU로 할당했을 때는 여러 CronJob들이 실행될 수 있으므로 클러스터 auto scaling을 하지 않아도 됩니다. 그러므로 가능한 한 리소스 요청량을 제한하는 것이 좋습니다.
출처
https://michael.bouvy.net/post/deep-dive-kubernetes-cronjob
https://aws.plainenglish.io/kubernetes-deep-dive-cronjob-4df5f64039d6
https://kubernetes.io/ko/docs/concepts/workloads/controllers/cron-jobs/
'🏋️♀️ DevOps, SRE' 카테고리의 다른 글
| [k8s] 당신의 pod에서 nslookup이 실패하는 이유 (0) | 2023.02.18 |
|---|---|
| 신입 데브옵스 (DevOps) 엔지니어 되기 - (1) (27) | 2023.02.06 |
| 주니어 DevOps 엔지니어가 바라 본 CPU 아키텍처 (docker pull이 안 된다!) (1) | 2022.10.21 |
| [AWS][DevOps] Terraform으로 EKS 환경 구성하기 - (1) (0) | 2022.08.14 |
| [DevOps] 내부 개발자 플랫폼 (IDP) : 조직이 더 효율적으로 일하는 방법 (0) | 2022.07.22 |